

Ask any finance leader about their Anaplan implementation, and you’ll hear the same observation: “The tool is great – but our data wasn’t ready.”
Over time we’ve seen this pattern repeatedly. Planning platforms are expected to solve forecasting challenges, yet the underlying data structures that support planning were never designed for that purpose.
We’ve worked on dozens of FP&A, S&OP, and TPM implementations across Australia, and the pattern is unmistakable. Organisations invest heavily in modern planning platforms like Anaplan, yet projects often take longer than expected and deliver less confidence than intended.
In most cases the limitation isn’t the platform. It’s the data environment beneath it.
Why planning platforms need strong data foundations
There’s clear logic behind investing in enterprise planning software. Your finance team struggles with version control in Excel. Your forecasting cycle takes too long. Getting alignment across departments is challenging. A modern, cloud-based planning platform addresses these pain points directly.
Anaplan can deliver on these promises. We’ve implemented solutions that have transformed how organisations plan and forecast.
The key is understanding what makes those implementations successful.
Even the most sophisticated planning platform can only operate on the data foundation supporting it. If that source data is fragmented across systems, if hierarchies don’t align, or reconciliation requires manual intervention, those challenges don’t disappear when Anaplan is implemented. They become constraints on what the platform can deliver.
The underlying challenge: fragmented data foundations in enterprise planning
When we conduct discovery for a new client, we start by mapping their data landscape.
What we typically find:
- Product hierarchies that don’t align across Finance, Sales, and Supply Chain – Finance calls it SKU-123, Sales calls it Product-ABC, and Supply Chain has it as Item-789 in the ERP
- Customer master data maintained in seven different spreadsheets – each with slightly different customer names, slightly different territories, and nobody quite sure which version is ‘source of truth’
- GL account structures that changed mid-year – making year-on-year comparisons a heroic manual reconciliation exercise
- Planning assumptions buried in email chains and tribal knowledge – because ‘that’s how the revenue forecast has always been done’
- Manual reconciliations between systems consuming 40% of the planning cycle – Finance spends more time making the numbers match than understanding what they mean
Sound familiar? This is the reality for most mid-to-large enterprises. Most source systems were never designed to speak the same language. Over years of mergers, reorganisations, and system upgrades, data architecture has become a patchwork quilt held together by Excel macros and institutional memory.
And then Anaplan is implemented on top of this unstable foundation.
Enterprise planning platforms are only the tip of the iceberg
Above the waterline (planning app):
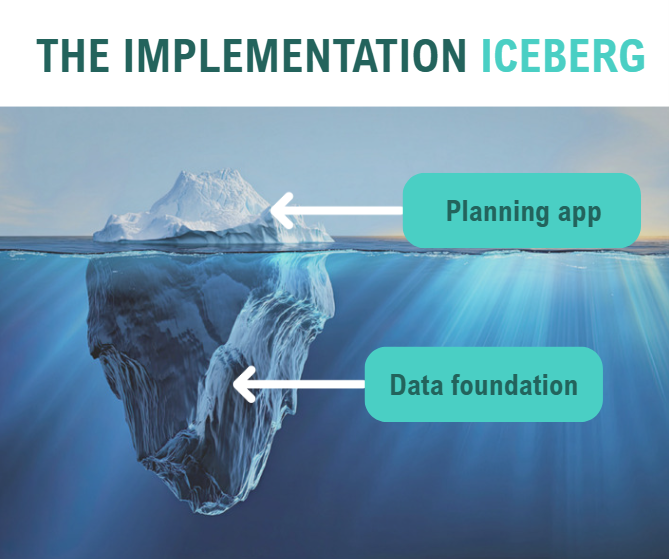
- User interface and dashboards
- Anaplan model design
- Business logic and calculations
- User training and adoption
Below the waterline (data foundation):
- Master data governance and harmonisation
- Source system integration architecture
- Data transformation and quality validation
- Automated reconciliation frameworks
- Audit trails and lineage documentation
- Error handling and monitoring
The visible part – the Anaplan app – is what gets demonstrated in the sales process. It’s what stakeholders are excited about. It’s what your project plan probably focuses on. But the success of the implementation ultimately depends on the structures beneath it: data governance, integration architecture, transformation logic and reconciliation controls.
What a data foundation for Anaplan and enterprise planning looks like
When we talk about building a data foundation for Anaplan, we mean creating a structured, automated pathway that takes raw data from source systems and transforms it into planning-ready information. This typically involves:
- Master data management
Establishing single, authoritative definitions for the core dimensions of your business—products, customers, accounts, employees, geographies. This doesn’t mean replacing your ERP’s master data. It means creating publish views—curated, validated versions of master data specifically designed for planning purposes. - Data integration architecture
Building automated pipelines that extract data from multiple source systems (ERPs, CRMs, legacy databases, spreadsheets), land it in a modern data platform, transform it according to business rules, and load it into Anaplan. This isn’t a one-off migration—it’s an ongoing, scheduled process that keeps your planning tool in sync with operational reality. - Transformation and validation
Creating transformation logic that maps source system codes to planning hierarchies, converts currencies, standardises units of measure, and applies business rules. Every transformation is documented, versioned, and includes validation checks. Source values are preserved alongside transformed values, enabling full auditability. - Reconciliation frameworks
Implementing control totals and checksums at every stage – source extraction, transformation, Anaplan load. This means stakeholders can verify that what landed in Anaplan matches what came from the ERP, and understand any differences through documented transformation rules. - Error handling and monitoring
Building intelligence into the integration: retry logic for transient failures, alerting when data quality issues are detected, automated notifications to data stewards when manual intervention is needed, comprehensive logging for troubleshooting.
This foundation doesn’t just make Anaplan work – it makes it trustworthy. Which is the whole point.
Why fixing data after an Anaplan implementation rarely works
We’ve seen this pattern countless times. The business case gets approved. The vendor is selected. The project plan shows Anaplan go-live in six months. Everyone is eager to start building the planning models.
Then someone raises concerns about master data quality. About integration complexity. About the 15 spreadsheets that currently feed the budget. The response: “We’ll handle that in Phase 2. Let’s just get Anaplan up and running first.”
This is the equivalent of pouring the foundation after the house has already been framed. It doesn’t work because planning models depend on stable data structures. Postponing the data work simply moves the problem later in the project – where it is more difficult and more expensive to resolve.
What actually happens:
Month 3: The project team discovers the product hierarchy in the ERP doesn’t match the planning hierarchy Finance needs. Meetings are scheduled to ‘resolve’ this. No one has authority to change the ERP. A mapping table is created in Excel.
Month 5: The first test load of actuals into Anaplan reveals that 12% of transactions can’t be mapped to the planning structure. The project manager asks IT to ‘clean up the data.’ IT responds that this is a business ownership issue. The steering committee gets involved.
Month 7: Planned go-live is pushed back. The team is building ‘workarounds’—manual processes to clean data before loading to Anaplan. The beautiful automated planning solution now requires three people spending two days each week preparing data.
Month 12: Anaplan is ‘live,’ but trust is low. Users question the numbers. Finance is still running parallel processes in Excel ‘just to be sure.’ Executive leadership is asking why they invested all this money to make things more complicated.
The cost of fixing the foundation after go-live is typically 3x the cost of building it properly from the start. Plus the opportunity cost of prolonged parallel processes, plus the reputational damage to the platform and project team.
The right sequence for a successful Anaplan implementation
Successful Anaplan implementations follow a deliberate sequence. Not because we like building suspense, but because you genuinely can’t do Step 5 until Steps 1-4 are stable.
Here’s the right order:
Step 1: Stabilise master data
Get clear on your core dimensions. Agree on hierarchies. Establish governance. Create publish views that Anaplan can reliably consume. This might expose uncomfortable truths about your current master data discipline—that’s the point. Better to know now than after you’ve built the Anaplan model.
Step 2: Build integration infrastructure
Establish a modern data platform (Snowflake, Databricks, or similar) and build reliable extraction pipelines from source systems. Create transformation layers. Implement quality validation. Get this working with master data first, before you touch transactional data.
Step 3: Design Anaplan structure
Start designing your Anaplan model or map data interfaces to pre-build Anaplan app. Because you know exactly what data you’ll receive, in what format, with what frequency, the model design can reflect reality instead of aspirations.
Step 4: Automate loading
Configure the connection from your data platform to Anaplan. Leverage Anaplan Data Orchestrator for rapid prototype of data pipelines. Use Anaplan’s Bulk API for ultimate scalability and auditability. Implement a reconciliation framework. Test with increasing data volumes. Monitor performance.
Step 5: Build planning logic
With clean, reliable data flowing into Anaplan, now you can focus on what Anaplan does brilliantly – sophisticated planning logic, driver-based models, scenario analysis, collaborative workflows.
Notice what happens when you follow this sequence: by the time you’re building planning logic, you’re not also fighting data quality fires. The model builders can focus on business requirements instead of data workarounds. User testing happens with real data, not samples. Go-live becomes a non-event because the data has been flowing reliably for weeks.
Why forecasting accuracy starts with data foundations
Anaplan is a powerful platform. But planning platforms cannot correct structural data problems. They simply expose them more clearly.
When supported by a strong data foundation, Anaplan can fundamentally improve how organisations plan, forecast and make decisions. We’ve seen it enable FP&A teams to shift from ‘explaining last month’ to ‘shaping next year.’ We’ve seen it give supply chain planners visibility they never thought possible. We’ve seen it turn trade promotions from a quarterly scramble into a strategic competitive advantage.
But every one of those success stories started the same way: with someone having the courage to say, “Before we implement Anaplan, we need to get our data foundation in order.”
That’s not a delay. That’s the fastest path to success.
Read more of our Planning Transformation in Practice series
- Planning transformation in practice: Part 1 – Making the case for change – why modernise planning now?
- Planning transformation in practice: Part 2 – Requirements gathering that drives real business impact
- Planning transformation in practice: Part 4 – Model design for scalability, performance and adoption
- Planning transformation in practice: Part 5 - Testing that proves your planning model is ready for the business
Find out more
- Planning transformation in practice: Making the case for change – why modernise planning now?
- Sustainable Business Planning – Our solutions
- Anaplan Partner delivering better planning for businesses in Australia & NZ
- Worldwide reach, local expertise: Global Anaplan Implementation Network
- Ready to start planning sustainably? Contact us.
Better Planning. Better Planet.